
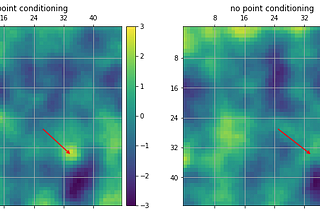

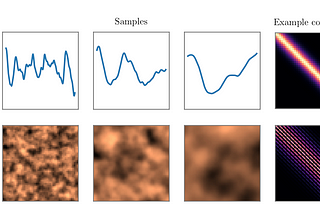


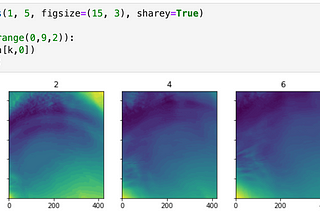

Rachel is a researcher in the Informatics Lab. Her current focus is on probabilistic super-resolution of weather models at convective scales.
Rachel is a researcher in the Informatics Lab. Her current focus is on probabilistic super-resolution of weather models at convective scales.